§ TSP-Enabled AI Agent Protocols
Specification Status: v1.0 Draft
Latest Draft:
https://github.com/trustoverip/aimwg-tsp-enabled-ai-agent-protocols
Editors:
Contributors:
- Participate:
- GitHub repo
- Commit history
§ Status of This Memo
This document contains a template specification for ToIP!.
Information about the current status of this document, any errata, and how to provide feedback on it, may be obtained at https://github.com/trustoverip/specification-template.
§ Copyright Notice
This specification is subject to the OWF Contributor License Agreement 1.0 - Copyright available at https://www.openwebfoundation.org/the-agreements/the-owf-1-0-agreements-granted-claims/owf-contributor-license-agreement-1-0-copyright.
If source code is included in the specification, that code is subject to the Apache 2.0 license unless otherwise marked. In the case of any conflict or confusion within this specification between the OWF Contributor License and the designated source code license, the terms of the OWF Contributor License shall apply.
These terms are inherited from the Technical Stack Working Group at the Trust over IP Foundation. Working Group Charter
§ Terms of Use
These materials are made available under and are subject to the OWF CLA 1.0 - Copyright & Patent license. Any source code is made available under the Apache 2.0 license.
THESE MATERIALS ARE PROVIDED “AS IS.” The Trust Over IP Foundation, established as the Joint Development Foundation Projects, LLC, Trust Over IP Foundation Series (“ToIP”), and its members and contributors (each of ToIP, its members and contributors, a “ToIP Party”) expressly disclaim any warranties (express, implied, or otherwise), including implied warranties of merchantability, non-infringement, fitness for a particular purpose, or title, related to the materials. The entire risk as to implementing or otherwise using the materials is assumed by the implementer and user. IN NO EVENT WILL ANY ToIP PARTY BE LIABLE TO ANY OTHER PARTY FOR LOST PROFITS OR ANY FORM OF INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES OF ANY CHARACTER FROM ANY CAUSES OF ACTION OF ANY KIND WITH RESPECT TO THESE MATERIALS, ANY DELIVERABLE OR THE ToIP GOVERNING AGREEMENT, WHETHER BASED ON BREACH OF CONTRACT, TORT (INCLUDING NEGLIGENCE), OR OTHERWISE, AND WHETHER OR NOT THE OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
§ RFC 2119
The Internet Engineering Task Force (IETF) is a large open international community of network designers, operators, vendors, and researchers concerned with the evolution of the Internet architecture and to ensure maximal efficiency in operation. IETF has been operating since the advent of the Internet using a Request for Comments (RFC) to convey “current best practice” to those organizations seeking its guidance for conformance purposes.
The IETF uses RFC 2119 to define keywords for use in RFC documents; these keywords are used to signify applicability requirements. ToIP has adapted the IETF RFC 2119 for use in the
The RFC 2119 keyword definitions and interpretation have been adopted. Those users who follow these guidelines SHOULD incorporate the following phrase near the beginning of their document: The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
RFC 2119 defines these keywords as follows:
- MUST: This word, or the terms “REQUIRED” or “SHALL”, mean that the definition is an absolute requirement of the specification.
- MUST NOT: This phrase, or the phrase “SHALL NOT”, means that the definition is an absolute prohibition of the specification.
- SHOULD: This word, or the adjective “RECOMMENDED”, means that there MAY exist valid reasons in particular circumstances to ignore a particular item, but the full implications MUST be understood and carefully weighed before choosing a different course.
- SHOULD NOT: This phrase, or the phrase “NOT RECOMMENDED” means that there MAY exist valid reasons in particular circumstances when the particular behavior is acceptable or even useful, but the full implications SHOULD be understood, and the case carefully weighed before implementing any behavior described with this label.
- MAY: This word, or the adjective “OPTIONAL”, means that an item is truly optional. One vendor MAY choose to include the item because a particular marketplace requires it or because the vendor feels that it enhances the product while another vendor MAY omit the same item.
Requirements include any combination of Machine-Testable Requirements and Human-Auditable Requirements. Unless otherwise stated, all Requirements MUST be expressed as defined in RFC 2119.
- Mandatories are Requirements that use a MUST, MUST NOT, SHALL, SHALL NOT or REQUIRED keyword.
- Recommendations are Requirements that use a SHOULD, SHOULD NOT, or RECOMMENDED keyword.
- Options are Requirements that use a MAY or OPTIONAL keyword.
An implementation which does not include a particular option MUST be prepared to interoperate with other implementations which include the option, recognizing the potential for reduced functionality. As well, implementations which include a particular option MUST be prepared to interoperate with implementations which do not include the option and the subsequent lack of function the feature provides.
§ Foreword
This publicly available specification was approved by the ToIP Foundation Steering Committee on [dd month yyyy must match date in subtitle above]. The ToIP permalink for this document is:
[permalink for this deliverable: see instructions on this wiki page]
The mission of the Trust over IP (ToIP) Foundation is to define a complete architecture for Internet-scale digital trust that combines cryptographic assurance at the machine layer with human accountability at the business, legal, and social layers. Founded in May 2020 as a non-profit hosted by the Linux Foundation, the ToIP Foundation has over 400 organizational and 100 individual members from around the world.
Any trade name used in this document is information given for the convenience of users and does not constitute an endorsement.
This document was prepared by the ToIP Technical Stack Working Group.
Any feedback or questions on this document should be directed to https://github.com/trustoverip/specification/issues
THESE MATERIALS ARE PROVIDED “AS IS.” The Trust Over IP Foundation, established as the Joint Development Foundation Projects, LLC, Trust Over IP Foundation Series (“ToIP”), and its members and contributors (each of ToIP, its members and contributors, a “ToIP Party”) expressly disclaim any warranties (express, implied, or otherwise), including implied warranties of merchantability, non-infringement, fitness for a particular purpose, or title, related to the materials. The entire risk as to implementing or otherwise using the materials is assumed by the implementer and user. IN NO EVENT WILL ANY ToIP PARTY BE LIABLE TO ANY OTHER PARTY FOR LOST PROFITS OR ANY FORM OF INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES OF ANY CHARACTER FROM ANY CAUSES OF ACTION OF ANY KIND WITH RESPECT TO THESE MATERIALS, ANY DELIVERABLE OR THE ToIP GOVERNING AGREEMENT, WHETHER BASED ON BREACH OF CONTRACT, TORT (INCLUDING NEGLIGENCE), OR OTHERWISE, AND WHETHER OR NOT THE OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
§ Introduction
§ The Rise of AI Agent Protocols
The rapid adoption of AI agents is driving a new generation of communication protocols designed for agent-to-tool and agent-to-agent interactions. Prominent among these are the Model Context Protocol (MCP), which connects AI assistants with external tools and data sources, and the Agent-to-Agent Protocol (A2A), which enables interoperability between autonomous agents built on different frameworks.
These protocols standardize how AI agents discover capabilities, invoke tools, exchange messages, and coordinate tasks. MCP defines schemas and transports (JSON-RPC over stdio and Streamable HTTP) that let models interoperate with tools and data sources. A2A specifies inter-agent messaging over HTTPS/SSE/JSON-RPC (with gRPC added in v0.3) to coordinate workflows across applications and providers. As deployments move from isolated AI assistants to multi-agent systems operating across organizational boundaries, the demand for protocols that address security and trust continues to grow.
§ The Security Gap: Retrofitting Web-Era Trust Models
Both MCP and A2A deliberately inherit the web-services security framework: HTTPS/TLS
for transport protection and OAuth 2.0/OIDC for authentication and authorization,
often modeled via OpenAPI securitySchemes. MCP adopted OAuth 2.1 with PKCE and
Dynamic Client Registration. A2A supports OAuth 2.0, OIDC, API keys, and mutual TLS,
declared via agent cards.
This pragmatic reliance on the web stack accelerates adoption. OAuth and OIDC are mature, widely deployed, and well-understood. However, as agents shift from experimental prototypes to autonomous, long-lived, cross-domain principals, this security foundation reveals structural gaps. Each gap reflects assumptions in the web stack that do not hold for autonomous AI agents.
The gaps fall into three categories:
§ Gap 1: Agent Identity
The web-services security framework does not provide a native identity model for AI agents. This manifests in four related problems.
Durability. The longer an autonomous agent operates, the more complex and valuable the problems it can solve. Long-duration agents accumulate context, build trust relationships, and develop reputation — all of which depend on stable identity. Stable identity is also a prerequisite for accountability: auditing agent actions, attributing decisions, and enforcing policy require an identifier that persists across sessions and interactions.
The web stack does not provide this. TLS certificates authenticate domains; OAuth 2.0/OIDC tokens identify users or service accounts within an Identity Provider’s (IdP’s) namespace. An agent’s identity is therefore tied to its current domain or IdP account — not to the agent as a persistent principal. If the identifier changes (due to redeployment, provider migration, or infrastructure changes), allowlists break, provenance chains are disrupted, and accumulated credentials are lost. Today, most agents are deployed ephemerally — not because enterprises prefer it, but because the control and identity mechanisms for long-lived autonomous agents do not yet exist. Durable identity is a prerequisite for the autonomous, long-horizon agents that agent protocol specifications and academic research envision.
Centralization. OAuth and OIDC depend on centralized Identity Providers. Identity federation (OpenID Federation, SAML) enables cross-domain trust, but requires bilateral administrative agreements that do not scale to open agent ecosystems, and still binds each agent’s identity to its organization’s IdP. IdP outages or compromises remain single points of failure. Agents operating as autonomous peers need to establish bilateral trust directly; the hierarchical client-server model of OAuth/OIDC does not accommodate peer-to-peer trust establishment.
Heterogeneity. The web stack uses multiple incompatible identifier systems (domain names in X.509, {issuer, subject} pairs in OAuth, vendor-specific service accounts). No current agent protocol defines a native, persistent identifier format for agents. Cross-vendor collaborations require brittle bilateral mappings. W3C Verifiable Credentials 2.0 defines machine-verifiable attestations bound to persistent identifiers, but these cannot be used effectively when the underlying identifiers are ephemeral and change across deployments.
Key management. In the web-services model, cryptographic keys are managed by the infrastructure — TLS keys belong to the domain operator, OAuth signing keys belong to the IdP. The agent does not control its own cryptographic material and cannot independently rotate keys while maintaining identity continuity. If the infrastructure operator is compromised, the agent has no independent cryptographic basis to re-establish trust.
The identity substrate and the trust model built on top of it are distinct problems. One might argue that using decentralized identifiers (DIDs) as the subject within existing OAuth flows would address these issues. However, substituting a DID for the subject claim does not change OAuth’s underlying trust model: tokens are still issued by centralized IdPs, scopes remain static, and the agent still does not control its own cryptographic keys.
§ Gap 2: Authentication and Delegated Authorization
OAuth 2.0 delegation lets a client (here, an agent) act on behalf of a resource owner. Current agent protocols rely on OAuth-style flows or OpenAPI-style auth for delegated authorization. When applied to autonomous AI agents, this model exhibits several well-documented problems.
-
Confused deputy: In agentic systems, a privileged agent may be manipulated into using its credentials on behalf of an unauthorized party. With bearer tokens, the agent cannot cryptographically verify who is making a request or whether the request is authorized — the token works regardless of who triggered it. The OWASP MCP Top 10 identifies confused deputy as a primary attack vector.
-
Prompt injection: LLM-based agents are susceptible to prompt injection, where malicious content in data (tool results, user inputs, retrieved documents) is crafted to be interpreted as instructions. This is fundamentally a model-level vulnerability, but the damage it causes is amplified by the lack of authenticated provenance in current protocols. When all data entering an agent’s context is unauthenticated, the agent and its runtime have no basis for applying differentiated trust policies. Authenticated provenance does not eliminate prompt injection, but it provides the infrastructure on which effective defenses can be built.
-
Token leakage and replay: OAuth access tokens are bearer tokens — anyone holding one can use it until expiry. DPoP (RFC 9449) mitigates this by binding tokens to a key pair via proof-of-possession, but the binding is between token and key, not between token and a verifiable agent identity. A DPoP-bound token proves the presenter holds the right key; it does not prove who the presenter is, what delegation chain authorized the request, or what task context it belongs to.
-
Static, coarse-grained scoping: OAuth scopes are predefined string tokens that cannot express the dynamic, contextual permissions AI agents require. An agent’s necessary permissions may change from one micro-action to the next, yet scopes are fixed at token issuance time.
-
No verifiable delegation chains: Agentic systems involve multi-hop delegation — user to orchestrator to specialized agents to tools. OAuth’s native model supports a single layer of delegation; Token Exchange (RFC 8693) enables re-delegation across service boundaries, but each hop trusts the previous authorization server rather than verifying a cryptographic chain. Downstream parties cannot independently audit the full delegation path.
-
Autonomy and lifecycle mismatch: OAuth’s security model assumes interactive human consent and persistent authorization relationships. Autonomous agents operate at machine speed, may run for hours, days, or months, and spawn sub-agents dynamically. OAuth’s consent-driven model does not scale with the frequency, duration, and system size of agentic workflows — leading to either overly broad long-lived tokens or impractical per-agent approval flows.
-
Scale of autonomous coordination: When agents number in the hundreds of thousands or millions — as demonstrated by recent agent-only platforms where over a million autonomous agents interact without human participation — trust decisions occur at a frequency and volume that human-mediated authorization cannot support. The security model must handle trust establishment, verification, and revocation at machine scale, not human scale.
The OAuth community is actively extending the framework — Rich Authorization Requests (RFC 9396), DPoP (RFC 9449), Token Exchange (RFC 8693), CIBA — and these are meaningful improvements. However, they address individual symptoms within the existing architectural model. The common root cause remains: the trust model depends on external centralized infrastructure rather than on the cryptographic relationship between the communicating endpoints.
This specification defines a protocol-native approach to authentication and delegation that addresses these structural issues, detailed in subsequent sections.
§ Gap 3: Data Authenticity and Provenance
The problem. TLS authenticates session endpoints; OAuth authenticates the client to the server. Neither provides data-level authenticity: individual messages, tool results, or data artifacts do not carry verifiable origin or integrity proofs once outside the session (RFC 8446 explicitly notes TLS authenticates endpoints, not application data). Trust is bound to ephemeral sessions, not to the data itself. When an agent retrieves data and passes it to another agent, downstream recipients cannot verify its authenticity without re-fetching from the original source. Multi-hop workflows cannot build durable provenance chains. For example, when an orchestrator agent delegates a task to a specialist agent that invokes a tool, the orchestrator receives the tool result through the specialist but has no cryptographic proof that the result originated from the tool and was not modified in transit.
For LLM-based agents, this gap is amplified: data and instructions occupy the same input stream. Skills, plugins, tool descriptions, and retrieved content are not merely data — they influence agent behavior. A malicious skill downloaded from a repository, a poisoned tool description, or compromised retrieved content can alter what the agent does. Without verified provenance, agents cannot distinguish trusted components from untrusted ones. The supply chain for agent capabilities — skills, extensions, integrations — is a data authenticity problem.
Agents need to produce, relay, and consume data that is self-authenticating: the authenticity proof travels with the data, independent of session, transport, or intermediary. This applies to messages, credentials, attestations, task results, and any artifact whose origin matters.
Existing approaches. JOSE (JWS/JWT) provides standardized signing primitives
with key identification (kid, jwk, x5c) and issuer/subject claims. However,
JOSE defines how to sign a payload and identify a key — not how agent protocols
should bind signatures to agent identifiers, how receiving agents resolve and
verify those identifiers, or how signatures chain across multiple hops to build
provenance. The key identification mechanisms inherit whatever limitations the
underlying identifier system has (the same issues described in Gap 1). Without a
protocol-level convention, each application re-implements signing with its own
choices, and signed payloads from one agent framework cannot be verified by
another.
What is needed. A protocol-level mechanism that binds data authenticity to the agent identity substrate: every message is signed using the sender’s cryptographic identifier, provenance is verifiable at each hop, and the mechanism is consistent across agent protocols. More broadly, when the identity substrate changes (as argued in Gap 1), the authentication, authorization, and data authenticity mechanisms built on top of it benefit from being native to that substrate rather than adapted from frameworks designed for a different identity model.
§ Metadata privacy
Even with TLS, network metadata — IP addresses, traffic timing, packet sizes, and communication patterns — remains exposed (RFC 7624). In multi-agent systems where frequent, structured exchanges are the norm, this metadata can reveal workflow structures, business relationships, and operational details. Deployments handling sensitive workflows may require metadata-minimizing routing mechanisms beyond what TLS provides.
§ Evidence from the Field
These gaps are not merely theoretical. MCP, as the more widely deployed protocol, has attracted the most scrutiny. The OWASP MCP Top 10 identifies confused deputy attacks — where agents with elevated privileges execute actions on behalf of unauthorized callers — as a primary attack vector, a direct consequence of bearer-token delegation without verified sender identity. Academic research found 5.5% of MCP servers exhibiting tool poisoning attacks through false tool descriptions. Scans of nearly 2,000 internet-exposed MCP servers found that all verified servers lacked any form of authentication.
Beyond deployment observations, industry practitioners, security researchers, standards bodies, and academic publications have independently concluded that the web-services security framework does not satisfy the trust requirements of AI agent communication. Published analyses from the ISACA, the OpenID Foundation, the Cloud Security Alliance, the Decentralized Identity Foundation, and researchers at ICML 2025 all reach this conclusion. An ICML 2025 position paper argues that authenticated delegation is critical and that current protocols cannot provide it.
§ The Need for a New Trust Layer
The gaps identified above indicate that securing AI agent communication requires more than adapting web-era authentication for agent protocols. A trust layer designed for the characteristics of autonomous agents would need to provide durable agent identity anchored in controller-managed cryptographic keys; data-level authenticity and provenance that travels with the data rather than the session; and cryptographically verifiable, auditable delegation chains with independent revocation at every hop.
The Trust Spanning Protocol (TSP), developed by the Trust over IP Project, is a message-oriented trust layer designed to address these requirements. TSP provides durable identity and authenticity properties across heterogeneous systems, anchored in long-term, controller-managed cryptographic identifiers. As long as endpoints use identifiers based on public key cryptography with a verifiable trust root, TSP ensures their messages are authentic.
TSP is designed to enable, not replace, agent protocols. It provides the trust layer that protocols such as MCP, A2A, and their successors currently lack by supplying:
-
Agent identity: Durable, controller-managed identifiers portable across infrastructures, supporting multiple identifier types without requiring a shared trust authority. Key rotation preserves identity continuity, and stable identifiers serve as anchors for trust signals — formal credentials, peer attestations, and authenticated word of mouth that accumulate over time.
-
Data authenticity and provenance: Message-level signatures bound to agent identifiers, making data artifacts verifiable across hops and over time — authenticity travels with the data, not the session.
-
Secure delegation: TSP’s authenticated messaging and verifiable identifiers provide the foundation for cryptographically verifiable delegation chains, where each hop can be independently audited and revoked. This specification defines delegation profiles built on these primitives.
By layering agent protocols over TSP, their existing developer ergonomics and interoperability are preserved while the trust substrate is strengthened. Tool discovery, invocation, and inter-agent coordination gain durable authenticity and verifiable trust properties that the web stack alone does not provide.
This specification defines how TSP integrates with AI agent communication protocols to address the security gaps described above. It specifies TSP-enabled profiles for agent identity, authentication, authorization, delegation, and secure messaging — defining a path from today’s web-stack-dependent agent protocols to a trust architecture designed for autonomous AI agents.
§ Scope
This specification defines an interoperable way of constructing and managing AI Agents, their authority and accountability, based on the Trust Spanning Protocol (TSP) to enhance the control and trustworthiness of AI Agents. For brevity, we call AI Agents (or simply Agents) developed using the methodilogy defined in this specification as TSP-Enabled Agents, or TEA for short. TEA supports autonomous, crytpographically strong, dynamic and Agent-native authorization and accountability schemes aimed for agent application scenarios in personal, enterprise or cloud uses.
§ Normative references
1. Wenjing Chu, Samuel M. Smith, Trust Spanning Protocol (TSP) Specification, Implementor’s Draft, Rev 2
2. Samuel M. Smith, Kevin Griffin, Key Event Receipt Infrastructure (KERI), v1.1, DOI: https://doi.org/10.5281/zenodo.18887102
3. Samuel M. Smith, Composable Event Streaming Representation (CESR)
§ Terms and Definitions
For the purposes of this document, the following terms and definitions apply.
ISO and IEC maintain terminological databases for use in standardization at the following addresses:
- ISO Online browsing platform: available at https://www.iso.org/obp
- IEC Electropedia: available at http://www.electropedia.org/
- Agent
- An agent is an anatonomous process over a period of time. An agent may be powered by various AI technologies which introduce capabilities such as use of natural languages, image and visual signal generation and understanding, use of programming and other online tools, reasoning, and so on. In this specification, we assume AI technologies may be used by agents, but they do not have to. We also assume AI agents may have persistent memory of data that they come to possess or have access to. Unless we make an explicit distinction in certain context, we use the terms agent and AI agent interchangably. Figure 1 provides a conceptual framework to define an agent’s main functional components and their interconnections among the components and with external systems.
- Trust Spanning Protocol
- The Trust Spanning Protocol (TSP) [1] is a foundational trust protocol that ensures endpoints (the TSP speakers), as identified by Verifiable Identifiers (VIDs), can have strong assurance of endpoint authenticity, message integrity, confidentiality and meta-data privacy. The TSP specification is a normative reference of this specification. Terms that are defined in [1] and used in this specification by references are not redefined but may be further constrained by this specification.
- TSP-Enabled Agent
- A TSP-Enabled Agent, or TEA, is an agent that is a TSP endpoint [1]. As defined in [1], a TSP endpoint has Verifiable Identifiers (VID), communicates with other TEAs through TSP. A TEA may also interact with other external systems that are not TEAs. A TEA is a unit that can be delegated with authority to take actions and be accounted for for effects of these actions. For convenience, we also allow the use of TEA Agent as equivalent to just TEA. This specification defines what a TEA MUST, SHOULD, or MAY do.
- Verifiable Identifier
- A Verifiable Identifier is a class of identifiers defined in the TSP specification [1]. The TEA uses a sub-class of VIDs that have stronger cryptographic verifiability for both control and provenance history. Such proof of continuous control of VID’s key material is necessary to enable long term durable relationships and reputation for TEAs. This specification defines detailed requirements to the VIDs used for TEAs.
- Wallet
- As a TSP endpoint, a TEA needs a method to store securely keys and other secrets. In this specification, we call such secure data store as a wallet, or a vault, or secure data store, interchangably.
- A TEA may be given by another party, e.g. an application that can interact with a human user or an administrative system or another party, the authorization to take certain scoped actions or access certain scoped resources on their behalf or for their benefits within a limited time horizon. The process that such authorization is given is called Delegation of Authority. In this specification, we define ways such delegation can be performed through TSP based messages. When an authorization is delegated to TEAs, such delegated authority can be accompanied or attached with explcitly expressed Duties also expressed in TSP based messages that are defined in this specification.
- Accountablity
- A TEA may be required to observe some rules or duties that are not automatically enforced or even explicitly stated. For example, computer systems often do not enforce by the system implementation Terms of Use agreements. Such terms can later be accounted after violation occured. Accountability is a process that can be used to investigate and discover whether certain such rules or duties were indeed observed by the TEA during a given time period. This process is usually performed after the fact.
- Audit
- Audit is a process of performing accountability over the history of a period of time.
§ TEA Reference Framework
As shown in the Reference Framework diagram below Figure 1, we define TEA Agents (or simply TEAs) as units of authorization and accountability that are identified by Verifiable Identifiers (VIDs) as defined in the TSP specification and further refined in this specification. TEA Agents communicate with other TEA Agents through TSP using VIDs.
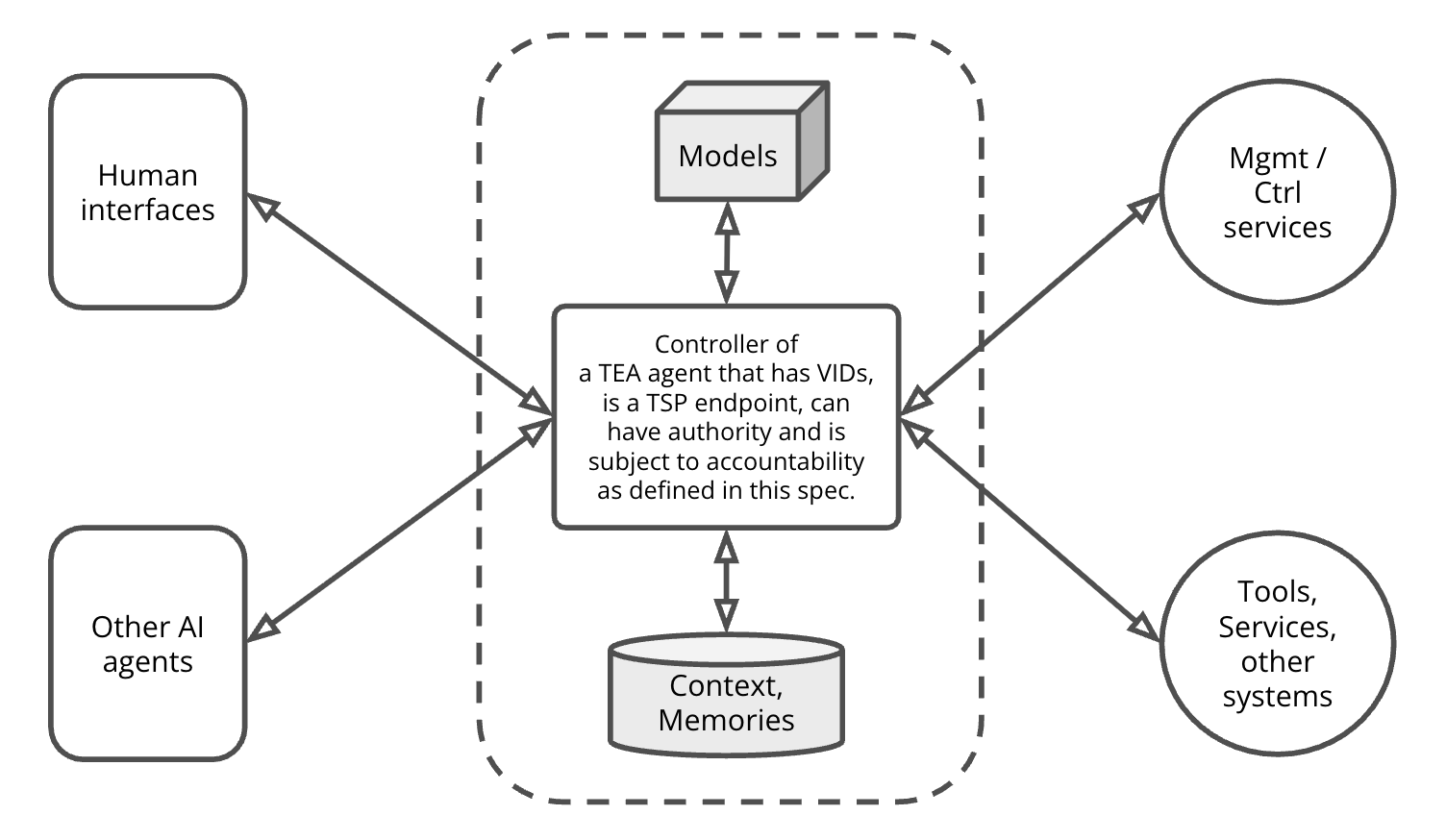
TEA Agents therefore MUST have modules to guard, maintain and use the VIDs and their associated secrets, such as keys. Practically, we may refer to these modules as Wallets and Vaults. In other words, TEA Agents MUST have wallets.
TEA Agents conceptually MAY be composed of a Controller, one or more AI models (e.g. LLM and other models), and some methods of implementing Agent-scoped memories: storage of long term information. This conceptual composition is useful in understanding and implementing the TEA, but it is not strictly required. As AI technologies evolve rapidly, the common composition of AI Agents may also change. The TEA method itself however is not dependent on a particular way of agent composition. For example, a TEA does not necessarily require either an LLM or a specific type of long term memory. That being said, this composition is useful to illustrate many challenges we are solving in the TEA method.
The Reference Framework diagram also captures other actors in an Agentic System which are important to define authorization and accountability. In the diagram, the “Human interfaces” box represents entities (such as an application or web browser) controlled by humans or human organizations interacting with the TEA as a “user”, for example, prompting or delegating. The “Management and Control Services” box represents external control systems, for example, administrative or operational controls. The “Tools, Services, other systems” box represents any external computational services. These boxes are external entities that we may reference in defining schemes for authorization and accountability.
In a TEA framework, external entities, such as a web service or a user interfacing mobile app, MAY also be TSP-Enabled. In such scenarios, these entities MAY behave just like a TEA. It is an important characteristic of the TEA framework, the overall system can expand into a network based on the common TSP layer.
The diagram also contains a box representing other AI Agents. These Agents MAY also be TEAs, or may not. When these are TEA Agents, this opens a flexible way of constructing more complex agentic systems by a group of networked TEA Agents, where the networking among them is based on TSP.
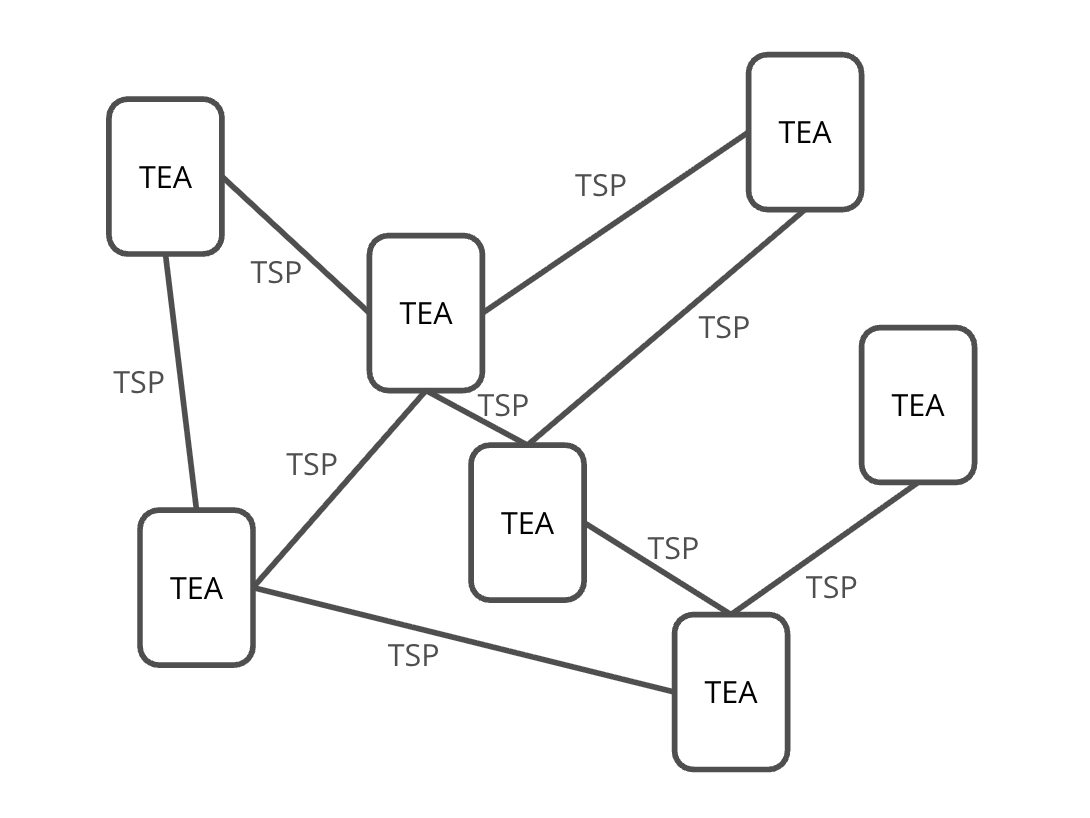
Combining these elements, we may construct a TSP based network where each node is a TSP-Enabled entity. For the purpose of this specification, all these TSP-Enabled nodes are TEAs. This is illustrated in the next diagram Figure 2.
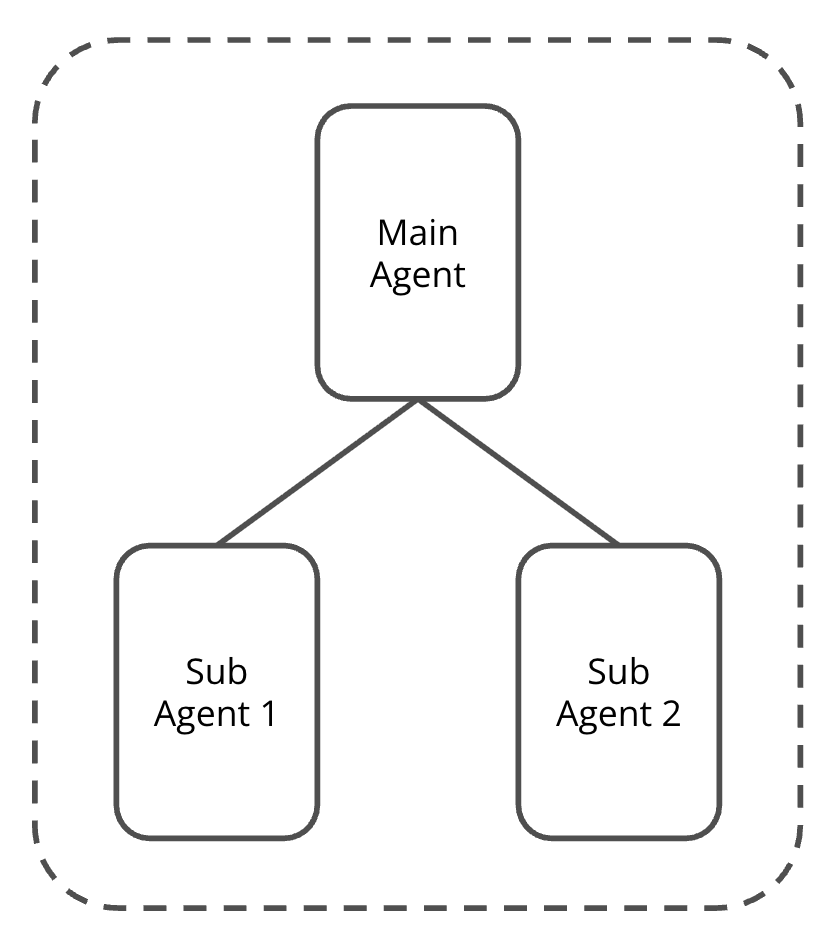
Finally, TEA Agents can be composite, as shown in the next diagram Figure 3 by a simple example. Composite TEAs are not limited to one way of composition. This diagram is only showing a simple example for illustration. When a TEA Agent is a composite Agent, there MUST be an entity (and therefore VID) representing the whole for the purpose and requirements of being a TEA Agent. This entity is overall who/what authorities are delegated to and accountability is assigned to.
§ TEAs
This section defines what agents need to do to be comformant TEAs.
A TEA is a TSP endpoint. As a TSP endpoint, the TSP specification [1[#TSP]] requires the agent MUST be secured as a distinct domain of control so that authority of operations and accountability can be uniquely assigned or attributed to a particular TEA. In the TEA Reference Framework Figure 1, the agent MUST contain a Controller (or TEA Controller) that is a conformant TSP endpoint. The agent MAY also include or interact with one or more AI models, and MAY include or interact with one or more persistent memory modules.
All context, memory access and tool use within this framework by the AI models MUST go through the Controller.
Note that an AI model served remotely by another operator may have its own context, memory or tool use outside of this framework. For the purpose of this specification, that is transparent and is considered part of the model’s behavior. If required, we will explicitly state if a model is embedded within the TEA’s domain of control or outside of it. Regardless, the model’s access to the context, memory, tools that reside within this TEA MUST go through the Controller.
The TEA Controller MUST contain a secured data store. We will refer this data store as its Wallet throughout this specification. Only the Controller has access to the Wallet. We defer the proper implementation of such wallets to #security-and-trust-considerations.
The TEA Controller MUST contain a TSP Gateway to send and receive TSP messages. This TEA can communicate with other TEAs or TSP endpoints with assured authenticity, message integrity, and confidentiality and potentially meta-data privacy through this TSP Gateway. All TSP messages going out or coming in MUST go through the TSP Gateway.
The TEA Controller MAY have other communication channels other than the TSP Gateway. All such communication channels MUST be rigorously secured in order to prevent threats from breaching the Controller. For further discussions, please refer to #security-and-trust-considerations.
The TEA Controller MUST have one or more public VIDs and MAY have additional private VIDs. It MUST designate at least one public VID as the Introduction VID (IVID) with which first time contacts can be made without prior trust relationships. It MUST also designate at least one public VID as the Authorization VID (AVID) that is used to assign authority and accountability. By default, the AVID and IVID are the same.
The TEA Controller MUST implement the mandatory delegation and accountability functions as defined in this specification.
§ Verifiable Identifiers (VIDs)
The TEA MUST use Verifiable Identifiers that are suitable for durable continuous identification. In order to meet this requirement, the VIDs MUST support key rotation and pre-rotation and allow the history of key rotations to be verifiable. TSP is interoperable with multiple VID formats but for ease of implementation and better interoperability, we prefer to choose a small number of VID schemes initially. This set MAY be extended in future.
The TEA MUST support these VIDs:
- did:webvh: See https://identity.foundation/didwebvh/v1.0/ (TODO: ADD reference)
The TEA MUST support the pre-rotation feature of the did:webvh.
§ TSP Gateway
The TSP Gateway MUST support both confidential and meta-data privacy functions that are optional in TSP. It MUST also support both NaCl and HPKE-base modes.
§ TSP Message Serializations
The TSP protocol specifies serialization using CESR which covers the envelope and nested and routed envelopes. In addition, it also specifies a set of control messages. For the payload data of a TSP message, TEA can use either native CESR, or JSON, CBOR or MsgPack serializations. This is a very useful feature especially when we have an existing higher layer protocols that we may want to layer over TSP.
§ TEA Signed Payload
A TEA may need messages carried by TSP with a sender signature tied to one of its VIDs, for example, the AVID. Even though all TSP messages are signed in the TSP level, that signature is not usable to a third party who is not the receiver. For authorization and accountability features, a TEA will need to present proofs to such third parties.
The TEA MUST implement the native signing scheme as follows:
TODO: ADD signature to payload TODO: Should this be part of TSP spec or here?
§ Transports
TSP is agnostic to transport layer choices. For TEA, we are also agnostic to transport layer options but it will be more convenient in integration with other protocols or systems if we choose the same common options.
The TEA MUST at least support these transport options:
- Streamable HTTP (SHTTP): as defined in the MCP specification (TODO: ADD reference)
- stdio: as defined in the MCP specification (TODO: ADD reference)
§ Layering Existing Protocols over TSP as Trust Tasks
TSP is designed to support higher layer protocols, called Trust Tasks, over TSP. Such trust tasks MAY be existing commonly used protocols ported over to TSP, e.g. MCP, or can be new protocols specified in one of the following sections, or in other specifications outside of this document.
Regardless of whether a Trust Task is an existing protocol ported to TSP or a new protocol defined in this specification, the following requirements apply. A Trust Task protocol MUST conduct all of its trust-establishing communication either directly over the TSP Gateway (the Trust Spanning Layer) or over another Trust Task protocol that itself runs over TSP. A Trust Task protocol MUST NOT re-implement the authenticity, message integrity, confidentiality, or metadata-privacy guarantees that TSP already provides; it relies on the TSP Gateway for them.
Where a Trust Task carries content that a third party — one that is not the TSP receiver — must be able to verify, it MUST carry that content as a TEA Signed Payload (see TEA Signed Payload) tied to the appropriate VID, typically the AVID.
§ Authenticated Exchange Protocol
The Authenticated Exchange Protocol is a Trust Task protocol, defined in this specification, by which two TEAs negotiate a request and the conditions under which it will be fulfilled. It is presented as a pattern: a deliberately minimal and flexible flow that more specialized Trust Tasks MAY follow or adapt.
The two roles are the Initiator (the TEA that opens the exchange) and the Responder. Both MUST be TSP endpoints identified by VIDs; either MAY be a composite TEA represented by a single VID, as defined in the TEA Reference Framework.
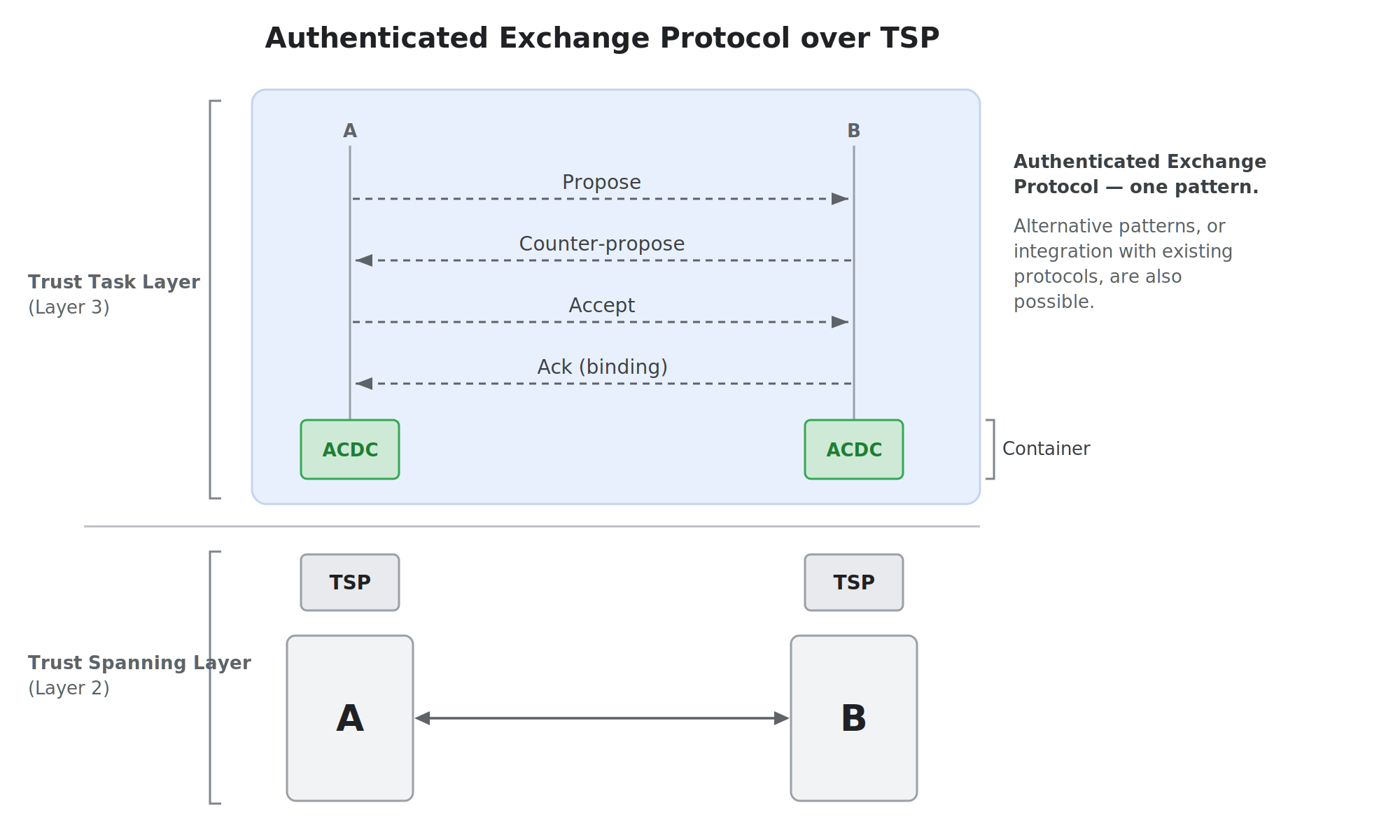
Because TSP at the Trust Spanning Layer has already mutually authenticated the two VIDs, the pattern does not perform party authentication; it concerns only the content of the negotiation. The pattern uses four message types:
- Propose — A party states a request together with the conditions or terms of its fulfilment. Either party MAY send a Propose. A Propose sent in response to a prior Propose is a counter-proposal that supersedes the terms under negotiation.
- Accept — A party signals agreement to the most recent Propose. An Accept is provisional until confirmed (see Requirement 6) and MUST reference the specific Propose it accepts.
- Ack — The offering party’s confirmation. The Ack is the act that binds the agreement.
- Withdraw — An optional message declining a Propose, or withdrawing an offer or a provisional acceptance, before it has been bound by an Ack.
A minimal exchange is
Propose → Accept → Ack. A flexible exchange isPropose → Propose (counter) → … → Accept → Ack, with zero or more counter-proposals in either direction.
The following requirements apply to any conforming instantiation of the pattern:
- Every message MUST be sent over the TSP between the Initiator’s VID and the Responder’s VID.
- Each message payload MUST be carried as an Authentic Chained Data Container (ACDC), serialized as permitted in TSP Message Serializations. Where a message must be verifiable by a third party it MUST be a TEA Signed Payload (see TEA Signed Payload) tied to the sender’s AVID. ACDC is the common interoperability primitive of the pattern regardless of the parties’ particular pattern of negotiation — their “pattern of speech.”
- An Accept MUST reference the specific Propose it accepts by a verifiable identifier (for example, the SAID of that Propose’s container).
- A party MUST treat only the most recent superseding Propose as the live offer; earlier proposals in the same exchange are no longer acceptable once superseded.
- Bounding invariant. Any message that leaves its sender exposed pending the counterparty’s next action MUST carry a validity bound. A Propose MUST carry a
validUntilbounding the time by which it may be accepted; an Accept MUST carry avalidUntilbounding the time by which the binding Ack must be effective. An offer or acceptance MUST NOT be open-ended. - Binding by affirmation. An Accept is provisional. The agreement binds only when the offering party’s Ack is effective within the Accept’s
validUntil. If no Ack is effective within that window, the acceptance lapses and nothing is bound. - Because the binding confirm necessarily follows acceptance, an Accept’s
validUntilwill normally fall later than the accepted Propose’svalidUntil. An implementation MUST NOT set an Accept’svalidUntilsuch that no Ack could be effective within it. - A Withdraw never binds or un-binds an agreement; it is effective only in the absence of a valid Ack. The offering party MAY Withdraw its live Propose at any time before it emits a binding Ack. The accepting party MAY Withdraw its provisional Accept, but that Withdraw is effective only if no valid Ack exists within the Accept’s validUntil; if a Withdraw and a valid Ack cross in flight, the Ack prevails and the Withdraw is void. The accepting party’s exposure to this outcome is bounded by the validUntil it set on its Accept.
- Timestamps used to evaluate
validUntilMUST be the signer’s own, carried in the message container, and evaluated within a defined clock-skew tolerance. The offering party’s signed Ack timestamp is authoritative for the time of binding. Binding is determined solely by the existence of a valid Ack within the Accept’s validUntil; it does not require comparing the Ack’s timestamp against any Withdraw, so no inter-party timestamp comparison is performed.
Editor’s note (binding model): Requirements 5–9 adopt a hybrid of explicit validity bounds and affirmative (confirm-binds) binding. The alternatives — validity bounds alone, or affirmative binding alone — are discussed in Design Rationale and Comparison. The working group should confirm the hybrid before these are finalized.
Other Trust Tasks MAY follow alternative patterns or port existing protocols over TSP (see Layering Existing Protocols over TSP as Trust Tasks and MCP over TSP); in every case the requirement is that they run over TSP and, where third-party verifiability is needed, carry their content as TEA Signed Payloads.
§ MCP over TSP
TODO
§ Delegation of Authorization and Duty
A TEA confers authority on another TEA by delegation. A delegation conveys two things together: an authorization — what the Delegate may do — and a duty — the obligations and conditions the Delegate accepts in exercising it, and for which it is accountable. Both are carried in a single authorization ACDC issued by the Delegator to the Delegate.
Consistent with the TEA Reference Framework, authority is delegated to, and accountability assigned to, the entity (and VID) representing the Delegate. A delegation is issued under, and verified against, the Delegator’s Authorization VID (AVID).
Because an authorization is itself verifiable information, a delegation can be delivered in band: the Authenticated Exchange Protocol settles the scope and the duties, and the binding act (the Ack) coincides with issuance of the authorization ACDC to the Delegate.
An authorization ACDC uses the three ACDC sections for distinct purposes:
- the attribute section names the Delegate (the Issuee) and the granted scope — the resource and ability conferred;
- the rule section carries the conditions as Ricardian clauses: both negative caveats that restrict the authority and affirmative duties the Delegate must fulfil;
- the edge section chains, via the I2I operator, to the ACDC that establishes the Delegator’s own authority. Requirements:
- A delegated authority MUST be expressed as an authorization ACDC issued by the Delegator (as Issuer) to the Delegate (as Issuee), under the Delegator’s AVID.
- The authorization ACDC MUST either (a) include an edge referencing the ACDC that establishes the Delegator’s own authority, using the I2I operator (or the DI2I operator where the Delegator’s identifier is itself delegated), so that the Issuer of the delegation is constrained to be the Issuee of the authority being delegated; or (b) be a root issuance, in which the Issuer is the authority that controls the resource and against which the relying party roots trust, and which therefore carries no incoming authority edge. Case (a) is the structural expression that a party may only delegate authority it holds; case (b) is the origin of that authority. A verifier MUST accept a root issuance only when it roots trust in that Issuer for the resource in question.
- A delegated authority MUST carry a
validUntilvalidity bound and MUST be revocable through its credential status registry. - Verification of a delegated authority MUST confirm, at the time of exercise, that every ACDC on the relevant chain is non-revoked and within its validity window.
§ Attenuated Re-delegation
Re-delegation MUST be supported, MUST be general and composable — chains of arbitrary depth, and authority composable from more than one source — and MUST be strictly attenuating: authority can only narrow as it is re-delegated. This is achieved with a capability model whose narrowing is intrinsic rather than merely checked.
An authorization is modeled as a capability object: a scope (a resource and an ability) drawn from a defined resource/ability model, and a set of caveats and duties drawn from a defined vocabulary, carried in the attribute and rule sections respectively. Capability objects MUST be defined as elements of a structure equipped with a partial order ≤ (“is at most as permissive as”) and a meet operation ∩ (intersection).
- A re-delegation MUST be expressed as a restriction relative to its source: the re-delegating authorization ACDC carries only the additional caveats, duties, and narrowed scope introduced at that step, not an independently restated capability.
- The effective authority of any node in a delegation chain is the meet (∩) of the source authority or authorities reached through its edges with the restriction expressed at that node. Because the meet is monotone (a ∩ b ≤ a), the effective authority of any node is necessarily no more permissive than each of its sources. Strict attenuation is therefore a property of the construction: provenance is supplied by the I2I edge (Requirement 2 above) and monotonic narrowing by the restriction-only encoding.
- An authority MAY be composed from multiple source authorities using ACDC m-ary edge-group operators. Under an
ANDedge-group, the effective authority requires all referenced sources and is the meet across them; under anORedge-group, any one valid source suffices; edge-groups MAY be nested to express arbitrary boolean combinations. The validity of a composed authority MUST be evaluated, at the time of exercise, over the live status (revocation and validity window) of each referenced source: underAND, revocation or expiry of any required source invalidates the composed authority; underOR, the authority remains valid while at least one referenced source is valid.
§ Closed Capability Core and Open Policy Extension
- This specification defines a closed capability core: a bounded caveat/duty vocabulary and a resource/ability model whose partial order and meet are total, deterministic, and decidable. A conforming verifier MUST compute the effective authority of a delegation chain by reduction — taking the meet along the chain — using only the closed-core semantics. This reduction requires no general policy engine and yields the same result for every conforming verifier.
- An implementation MAY extend the rule section with an open policy expression for conditions not expressible in the closed core. Open caveats MUST be evaluated by the designated policy model, and MUST only further restrict the effective authority; they MUST NOT broaden the authority computed from the closed core.
- Soundness property. For any delegation chain expressed solely with the closed capability core, no node’s effective authority can exceed the authority of its root or roots. This property is intended to be stated and proven as part of Security and Trust Considerations.
Editor’s note (open items): The concrete closed-core caveat/duty vocabulary and resource/ability lattice are not yet fixed; they should be chosen to keep the meet operation tractable. The semantics for merging caveats and duties across an
ANDcomposition of multiple sources must be specified or explicitly deferred to the open policy model. Existing capability and chained-authorization patterns in the KERI/ACDC community should be reviewed before fixing an encoding.
§ Accountability
Authorization and accountability are distinct functions served by the same structure. A chain of ACDCs, read from root to leaf, expresses the delegation and provenance of authority; read from leaf to root, the same chain is the accountability trace. A TEA is therefore a single unit of authorization and accountability because both derive from one cryptographic structure.
Accountability is retrospective and evidentiary: it answers who agreed to or did what, and whether it can be proven after the fact. The ACDC chain provides accountability directly — each container is signed, chained, and non-repudiable — and, when carried as a TEA Signed Payload tied to the AVID, it can be presented to and verified by a third party that did not observe the original interaction.
Requirements:
- An authorization or agreement that must be accountable to a third party MUST be recorded as a TEA Signed Payload (see TEA Signed Payload) tied to the responsible party’s AVID.
- The accountability chain of any authority a TEA holds or exercises MUST terminate in a principal — a natural person or organization — that can bear accountability. A TEA MUST NOT be the terminal responsible party for an authority.
- An authorization MUST NOT be inferred solely from a record that an agreement occurred; conferral of authority requires an authorization ACDC as defined in Delegation of Authorization and Duty.
§ Worked Example: Delegated Service Access
This section is informative. It illustrates the preceding clauses with the simplest end-to-end scenario: a principal who authorizes an agent to use a service on the principal’s behalf.
§ Actors
- BookingService (S) — the Service API and Relying Party. As the owner of the resource being accessed, S is the root of authority over that resource and is also the party that verifies access to it.
- Alice — the Principal: the account holder at S and the accountable party. Alice holds
AVID_Alice. - Agent — Alice’s TEA and the Delegate, holding
AVID_Agent.
Because the resource owner is the natural root of authority, the chain of authority runs S → Alice → Agent, and every link is a uniform I2I delegation. S therefore verifies a chain that roots in its own issuance, needing no external trust anchor — which mirrors how account-based services actually work.
§ The authority chain
Hop 1 — Cred_S→Alice (root issuance). S authorizes Alice as the holder of her account. This is the root of the chain: S owns the resource, so this issuance has no incoming authority edge.
Cred_S→Alice
i: AVID_S # Issuer = the service (root of authority)
a:
i: AVID_Alice # Issuee = Alice
scope:
resource: bookingservice:account/alice
ability: [ create-booking, cancel-booking, view ]
r: { account terms ... }
ri: <S's status registry>
(no authority edge — S is the root of authority over the resource)
Hop 2 — Cred_Alice→Agent (I2I re-delegation, attenuated). Alice re-delegates a narrowed slice to her Agent. The grant is expressed as a restriction relative to the parent: a smaller ability set, plus caveats and a duty.
Cred_Alice→Agent
i: AVID_Alice # Issuer = Alice
a:
i: AVID_Agent # Issuee = the Agent
scope:
resource: bookingservice:account/alice
ability: [ create-booking ] # attenuated: subset of Alice's abilities
r:
caveats: { maxAmount: 500 USD, category: [ flights ] }
duties: { report: { to: AVID_Alice, on: each-booking } }
e:
auth:
n: <SAID of Cred_S→Alice> # far node = the parent authority
o: I2I # Issuer(this) MUST be Issuee(parent): Alice = Alice ✓
validUntil: <now + 7 days>
ri: <Alice's status registry>
§ Effective authority (the meet)
The Agent’s effective authority is the meet (∩) along the chain:
Alice's authority : { create-booking, cancel-booking, view } on alice's account
∩ Alice→Agent delta : ability ⊆ { create-booking }; amount ≤ $500; category = flights; within 7 days
= Agent's authority : create-booking on alice's account, ≤ $500, flights only, until T+7d
This is strictly ≤ Alice’s authority, which is ≤ S’s grant — the narrowing is intrinsic because each hop carries only a restriction. A request to book a $420 flight falls inside this set and is permitted; a $900 booking, a hotel, or a request after day 7 would not.
§ Runtime

- Delegation. Over their TSP channel, Alice and the Agent run the Authenticated Exchange Protocol to settle the terms; Alice’s binding Ack issues
Cred_Alice→Agentto the Agent in band. - Access. The Agent opens an exchange with S, proposing a concrete booking (a $420 flight) and presenting the chain
{ Cred_Alice→Agent ▸ Cred_S→Alice }as a TEA Signed Payload (see TEA Signed Payload) tied toAVID_Agent. - Verification. S confirms the chain roots in its own issuance (
AVID_S); that the I2I edge holds (Alice is the Issuee of the authority she re-delegated); that the leaf Issuee is the TSP counterparty presenting it; that the meet of the chain covers the requested operation; and that no ACDC on the chain is revoked or past itsvalidUntil. S then Accepts/Acks and creates the booking. - Duty. The Agent discharges its duty by reporting the booking to Alice as a signed payload.
§ What the example demonstrates
- The service is both the root and the verifier. S validates a chain rooted in its own grant, so no external anchor is needed — the base “root issuance” case lands naturally on the resource owner, and the normative text needs no special “root principal” carve-out beyond “the chain roots in the authority that controls the resource.”
- Re-delegation is a uniform I2I hop, and attenuation is intrinsic: the Agent cannot exceed what Alice holds, which cannot exceed what S granted.
- One chain, two readings. Read S → Agent, it is the delegation of authority; read Agent → S, it is the accountability trace, terminating in Alice — a principal, never the Agent.
§ Design Rationale and Comparison
This section is non-normative. It situates the design choices above against commonly used schemes for the benefit of reviewers and implementers; it imposes no requirements.
§ Negotiation and binding
The Authenticated Exchange’s binding model is, in effect, a peer-to-peer two-phase commit: the offering party’s Ack is the commit decision. Unlike classical two-phase commit it needs no coordinator and does not block on a failed coordinator, because the validUntil bounds turn an unresponsive counterparty into a clean lapse rather than an indefinite hang — the same hardening production systems add to two-phase commit through presumptive-abort timeouts.
Race resolution and the inconsistency window. The asymmetry between Withdraw and Ack is the same asymmetry two-phase commit draws between a participant’s vote and the coordinator’s decision. An Accept is a vote-commit: once cast, the accepting party honors it until its validUntil lapses, and cannot unilaterally abort a decision the offering party may still make within that window. The offering party’s Ack is the commit decision, and it is supreme — a Withdraw is effective only in the absence of a valid Ack, so a Withdraw that races a binding Ack simply loses. This is what makes the resolution deterministic without a coordinator and without comparing the two parties’ self-signed timestamps against each other: binding turns solely on whether a valid Ack exists within the window, a question with one answer that an adversary cannot tilt by backdating. The price is that the accepting party cannot be certain a late Withdraw will land; it may lose to an Ack already in flight. That uncertainty is exactly the residual bounded inconsistency window noted below — it is bounded by the validUntil the accepting party itself chose, and no coordinator-free commit can eliminate it.
The closest market analogue is request-for-quote trading with “last look,” in which a maker may reject a deal within a window after a taker hits a time-bounded quote. Last look is widely criticized because it is one-sided: it grants the maker a free option at the taker’s expense. The symmetric validUntil on both Propose and Accept answers that critique — it bounds the offeror’s confirm window the way it bounds the acceptor’s offer window — so the design can be characterized as affirmative binding without the last-look asymmetry.
Hashed-timelock contracts (HTLCs) for atomic swaps are a closer fit on the symmetry of timeouts but solve a different problem: HTLCs provide atomic exchange of value, whereas the Authenticated Exchange provides agreement on terms. The Ack binds what the parties agreed; it does not guarantee performance. Where atomic execution of an agreed obligation is required, that is a separate Trust Task layered above the negotiation. Token-expiry schemes (OAuth/JWT exp/nbf) informed the validUntil mechanism but are not negotiations; GNAP is the closest negotiation-of-authority analogue but is authorization-server-mediated and centralized, whereas this design is peer-to-peer over TSP with the outcome captured in a portable ACDC.
| Scheme | How offers are bounded | What binds | Durable verifiable record? | Notable weakness |
|---|---|---|---|---|
| Two-phase commit | Coordinator timeout (often absent → blocking) | Coordinator commit | No (ephemeral logs) | Needs a trusted coordinator; blocks on its failure |
| RFQ + last look | Quote firm-for-N-seconds | Maker confirm after taker hits | Venue logs, not portable | Asymmetric free option for the maker |
| HTLC / atomic swap | On-chain timelocks | Preimage before timeout | Yes (on-ledger) | Needs a ledger and the asset; value exchange only |
| OAuth2 / JWT | exp / nbf in token |
One-shot issuance | Token verifiable, not a negotiation record | Clock-dependent; not a negotiation |
| GNAP | Protocol-level | Grant issuance | Server-side | Authorization-server-mediated; centralized |
| IPEX | Not expiry-first | grant/admit | Yes (ACDC) | Disclosure only; expiry not first-class; draft incomplete |
| Authenticated Exchange | Symmetric validUntil on Propose and Accept |
Affirmative Ack (confirm-binds) | Yes (ACDC-chained, portable) | Extra round-trip; clock-skew residue; binds terms, not performance |
The distinctive position of the Authenticated Exchange is that it is the only one of these combining decentralized peer operation (no coordinator, certificate authority, venue, or ledger), symmetric exposure bounding, and a portable non-repudiable record verifiable after the fact. The honest costs are an extra round-trip, a residual bounded inconsistency window that no timeout-based commit can fully eliminate — the window in which an accepting party’s Withdraw may lose to a racing Ack, bounded by its own validUntil — and a remaining clock dependence that affirmative binding reduces but does not remove.
§ Delegation and attenuation
The capability model draws on established authorization-capability designs. SPKI/SDSI is the formal precedent for computing effective authority as the intersection of authorizations along a delegation chain (tag intersection / certificate-chain reduction); the closed-core “meet along the chain” rule is the same idea over ACDC edges. Macaroons achieve strict attenuation structurally by making caveats append-only — a restriction can be added but not removed — which is the model for the restriction-only re-delegation encoding. UCAN provides decentralized, DID-native capability chains with an attenuation-checked subsumption order, and ZCAP-LD is the linked-data cousin in which caveats accumulate down the chain.
The closest ACDC-native precedent is the GLEIF vLEI credential chain (a role credential chained to a Legal Entity credential chained to a Qualified vLEI Issuer credential), itself a delegation-of-authority chain expressed entirely through ACDC edges with the I2I operator. The principal way this specification goes beyond IPEX — the nearest ACDC-native exchange protocol — is that IPEX provides no validity bounds or attenuation semantics at all (its security considerations were never completed), so the bounding and strict-attenuation apparatus here is additive rather than a restatement.
The rationale for favouring a closed capability core in this specification is that it is the part whose security can be proven: a capability structure with a defined meet supports a soundness theorem — no chain of delegations can yield authority exceeding its root — which is a materially stronger guarantee than re-checking attenuation with a general policy engine on every exercise. The open policy extension remains available for conditions the closed core cannot express, on the understanding that those conditions trade the structural guarantee for an evaluation dependency.
§ Security and Trust Considerations
TODO
§ Annex
Annex content